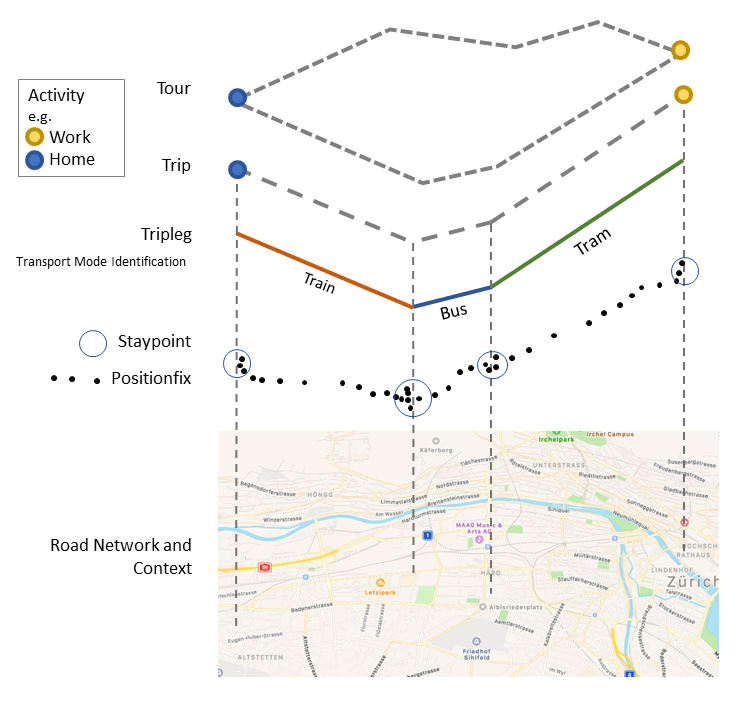
Model
In trackintel, tracking data is split into several classes. It is not generally
assumed that data is already available in all these classes, instead, trackintel
provides functionality to generate everything starting from the raw GPS positionfix data
(consisting of at least (user_id, tracked_at, longitude, latitude) tuples).
positionfixes: Raw GPS data.
staypoints: Locations where a user spent a minimal time.
triplegs: Segments covered with one mode of transport.
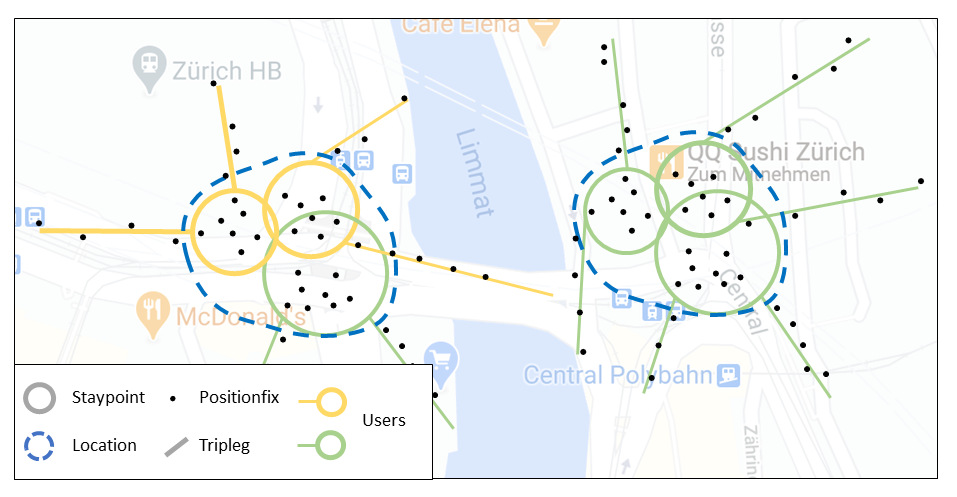
locations: Clustered staypoints.
trips: Segments between consecutive activity staypoints (special staypoints that are not just waiting points).
tours: Sequences of trips which start and end at the same location (if the column ‘journey’ is True, this location is home).
An example plot showing the hierarchy of the trackintel data model can be found below:
The image below explicitly shows the definition of locations as clustered staypoints, generated by one or several users.
A detailed (and SQL-specific) explanation of the different classes can be found under Data Model (SQL).
GeoPandas Implementation
In trackintel, we assume that all these classes are available as (Geo)Pandas (Geo)DataFrames. While we do not extend the given DataFrame constructs, we provide accessors that validate that a given DataFrame corresponds to a set of constraints, and make functions available on the DataFrames. For example:
df = trackintel.read_positionfixes_csv('data.csv')
df.as_positionfixes.generate_staypoints()
This will read a CSV into a format compatible with the trackintel understanding of a collection of
positionfixes, and the second line will wrap the DataFrame with an accessor providing functions such
as generate_staypoints(). You can read up more on Pandas accessors in the Pandas documentation.
Available Accessors
The following accessors are available within trackintel.
PositionfixesAccessor
- class trackintel.model.positionfixes.PositionfixesAccessor(pandas_obj)[source]
A pandas accessor to treat (Geo)DataFrames as collections of Positionfixes.
This will define certain methods and accessors, as well as make sure that the DataFrame adheres to some requirements.
Requires at least the following columns: [‘user_id’, ‘tracked_at’]
Requires valid point geometries; the ‘index’ of the GeoDataFrame will be treated as unique identifier of the Positionfixes.
For several usecases, the following additional columns are required: [‘elevation’, ‘accuracy’ ‘staypoint_id’, ‘tripleg_id’]
Notes
In GPS based movement data analysis Positionfixes are the smallest unit of tracking and represent timestamped locations.
‘tracked_at’ is a timezone aware pandas datetime object.
Examples
>>> df.as_positionfixes.generate_staypoints()
- calculate_distance_matrix(Y=None, dist_metric='haversine', n_jobs=0, **kwds)[source]
Calculate a distance matrix based on a specific distance metric.
If only X is given, the pair-wise distances between all elements in X are calculated. If X and Y are given, the distances between all combinations of X and Y are calculated. Distances between elements of X and X, and distances between elements of Y and Y are not calculated.
- Parameters
X (GeoDataFrame (as trackintel staypoints or triplegs)) –
Y (GeoDataFrame (as trackintel staypoints or triplegs), optional) –
dist_metric ({'haversine', 'euclidean', 'dtw', 'frechet'}) –
The distance metric to be used for calculating the matrix.
For staypoints, common choice is ‘haversine’ or ‘euclidean’. This function wraps around the
pairwise_distancefunction from scikit-learn if only X is given and wraps around thescipy.spatial.distance.cdistfunction if X and Y are given. Therefore the following metrics are also accepted:via
scikit-learn: [‘cityblock’, ‘cosine’, ‘euclidean’, ‘l1’, ‘l2’, ‘manhattan’]via
scipy.spatial.distance: [‘braycurtis’, ‘canberra’, ‘chebyshev’, ‘correlation’, ‘dice’, ‘hamming’, ‘jaccard’, ‘kulsinski’, ‘mahalanobis’, ‘minkowski’, ‘rogerstanimoto’, ‘russellrao’, ‘seuclidean’, ‘sokalmichener’, ‘sokalsneath’, ‘sqeuclidean’, ‘yule’]For triplegs, common choice is ‘dtw’ or ‘frechet’. This function uses the implementation from similaritymeasures.
n_jobs (int) – Number of cores to use: ‘dtw’, ‘frechet’ and all distance metrics from pairwise_distance (only available if only X is given) are parallelized.
**kwds – optional keywords passed to the distance functions.
- Returns
D – matrix of shape (len(X), len(X)) or of shape (len(X), len(Y)) if Y is provided.
- Return type
np.array
Examples
>>> calculate_distance_matrix(staypoints, dist_metric="haversine") >>> calculate_distance_matrix(triplegs_1, triplegs_2, dist_metric="dtw")
- property center
Return the center coordinate of this collection of positionfixes.
- generate_staypoints(method='sliding', distance_metric='haversine', dist_threshold=100, time_threshold=5.0, gap_threshold=15.0, include_last=False, print_progress=False, exclude_duplicate_pfs=True, n_jobs=1)[source]
Generate staypoints from positionfixes.
- Parameters
positionfixes (GeoDataFrame (as trackintel positionfixes)) – The positionfixes have to follow the standard definition for positionfixes DataFrames.
method ({'sliding'}) – Method to create staypoints. ‘sliding’ applies a sliding window over the data.
distance_metric ({'haversine'}) – The distance metric used by the applied method.
dist_threshold (float, default 100) – The distance threshold for the ‘sliding’ method, i.e., how far someone has to travel to generate a new staypoint. Units depend on the dist_func parameter. If ‘distance_metric’ is ‘haversine’ the unit is in meters
time_threshold (float, default 5.0 (minutes)) – The time threshold for the ‘sliding’ method in minutes.
gap_threshold (float, default 15.0 (minutes)) – The time threshold of determine whether a gap exists between consecutive pfs. Consecutive pfs with temporal gaps larger than ‘gap_threshold’ will be excluded from staypoints generation. Only valid in ‘sliding’ method.
include_last (boolean, default False) – The algorithm in Li et al. (2008) only detects staypoint if the user steps out of that staypoint. This will omit the last staypoint (if any). Set ‘include_last’ to True to include this last staypoint.
print_progress (boolean, default False) – Show per-user progress if set to True.
exclude_duplicate_pfs (boolean, default True) – Filters duplicate positionfixes before generating staypoints. Duplicates can lead to problems in later processing steps (e.g., when generating triplegs). It is not recommended to set this to False.
n_jobs (int, default 1) – The maximum number of concurrently running jobs. If -1 all CPUs are used. If 1 is given, no parallel computing code is used at all, which is useful for debugging. See https://joblib.readthedocs.io/en/latest/parallel.html#parallel-reference-documentation for a detailed description
- Returns
pfs (GeoDataFrame (as trackintel positionfixes)) – The original positionfixes with a new column
[`staypoint_id`].sp (GeoDataFrame (as trackintel staypoints)) – The generated staypoints.
Notes
The ‘sliding’ method is adapted from Li et al. (2008). In the original algorithm, the ‘finished_at’ time for the current staypoint lasts until the ‘tracked_at’ time of the first positionfix outside this staypoint. Users are assumed to be stationary during this missing period and potential tracking gaps may be included in staypoints. To avoid including too large missing signal gaps, set ‘gap_threshold’ to a small value, e.g., 15 min.
Examples
>>> pfs.as_positionfixes.generate_staypoints('sliding', dist_threshold=100)
References
Zheng, Y. (2015). Trajectory data mining: an overview. ACM Transactions on Intelligent Systems and Technology (TIST), 6(3), 29.
Li, Q., Zheng, Y., Xie, X., Chen, Y., Liu, W., & Ma, W. Y. (2008, November). Mining user similarity based on location history. In Proceedings of the 16th ACM SIGSPATIAL international conference on Advances in geographic information systems (p. 34). ACM.
- generate_triplegs(staypoints=None, method='between_staypoints', gap_threshold=15)[source]
Generate triplegs from positionfixes.
- Parameters
positionfixes (GeoDataFrame (as trackintel positionfixes)) – The positionfixes have to follow the standard definition for positionfixes DataFrames. If ‘staypoint_id’ column is not found, ‘staypoints’ needs to be given.
staypoints (GeoDataFrame (as trackintel staypoints), optional) – The staypoints (corresponding to the positionfixes). If this is not passed, the positionfixes need ‘staypoint_id’ associated with them.
method ({'between_staypoints'}) – Method to create triplegs. ‘between_staypoints’ method defines a tripleg as all positionfixes between two staypoints (no overlap). This method requires either a column ‘staypoint_id’ on the positionfixes or passing staypoints as an input.
gap_threshold (float, default 15 (minutes)) – Maximum allowed temporal gap size in minutes. If tracking data is missing for more than gap_threshold minutes, a new tripleg will be generated.
- Returns
pfs (GeoDataFrame (as trackintel positionfixes)) – The original positionfixes with a new column
[`tripleg_id`].tpls (GeoDataFrame (as trackintel triplegs)) – The generated triplegs.
Notes
Methods ‘between_staypoints’ requires either a column ‘staypoint_id’ on the positionfixes or passing some staypoints that correspond to the positionfixes! This means you usually should call
generate_staypoints()first.The first positionfix after a staypoint is regarded as the first positionfix of the generated tripleg. The generated tripleg will not have overlapping positionfix with the existing staypoints. This means a small temporal gap in user’s trace will occur between the first positionfix of staypoint and the last positionfix of tripleg: pfs_stp_first[‘tracked_at’] - pfs_tpl_last[‘tracked_at’].
Examples
>>> pfs.as_positionfixes.generate_triplegs('between_staypoints', gap_threshold=15)
- get_speed()[source]
Compute speed per positionfix (in m/s)
- Parameters
positionfixes (GeoDataFrame (as trackintel positionfixes)) – The positionfixes have to follow the standard definition for positionfixes DataFrames.
- Returns
pfs – The original positionfixes with a new column
[`speed`]. The speed is given in m/s- Return type
GeoDataFrame (as trackintel positionfixes)
Notes
The speed at one positionfix is computed from the distance and time since the previous positionfix. For the first positionfix, the speed is set to the same value as for the second one.
- plot(out_filename=None, plot_osm=False, axis=None)[source]
Plots positionfixes (optionally to a file).
If you specify
plot_osm=Truethis will useosmnxto plot streets below the positionfixes. Depending on the extent of your data, this might take a long time. The data gets transformed to wgs84 for the plotting.- Parameters
positionfixes (GeoDataFrame (as trackintel positionfixes)) – The positionfixes to plot.
out_filename (str, optional) – The file to plot to, if this is not set, the plot will simply be shown.
plot_osm (bool, default False) – If this is set to True, it will download an OSM street network and plot below the staypoints.
axis (matplotlib.pyplot.Artist, optional) – axis on which to draw the plot
Examples
>>> pfs.as_positionfixes.plot('output.png', plot_osm=True)
- to_csv(filename, *args, **kwargs)[source]
Write positionfixes to csv file.
Wraps the pandas to_csv function, but strips the geometry column and stores the longitude and latitude in respective columns.
- Parameters
positionfixes (GeoDataFrame (as trackintel positionfixes)) – The positionfixes to store to the CSV file.
filename (str) – The file to write to.
args – Additional arguments passed to pd.DataFrame.to_csv().
kwargs – Additional keyword arguments passed to pd.DataFrame.to_csv().
Notes
“longitude” and “latitude” is extracted from the geometry column and the orignal geometry column is dropped.
Examples
>>> ps.as_positionfixes.to_csv("export_pfs.csv")
- to_postgis(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)[source]
Stores positionfixes to PostGIS. Usually, this is directly called on a positionfixes DataFrame (see example below).
- Parameters
positionfixes (GeoDataFrame (as trackintel positionfixes)) – The positionfixes to store to the database.
name (str) – The name of the table to write to.
con (str, sqlalchemy.engine.Connection or sqlalchemy.engine.Engine) – Connection string or active connection to PostGIS database.
schema (str, optional) – The schema (if the database supports this) where the table resides.
if_exists (str, {'fail', 'replace', 'append'}, default 'fail') –
How to behave if the table already exists.
fail: Raise a ValueError.
replace: Drop the table before inserting new values.
append: Insert new values to the existing table.
index (bool, default True) – Write DataFrame index as a column. Uses index_label as the column name in the table.
index_label (str or sequence, default None) – Column label for index column(s). If None is given (default) and index is True, then the index names are used.
chunksize (int, optional) – How many entries should be written at the same time.
dtype (dict of column name to SQL type, default None) – Specifying the datatype for columns. The keys should be the column names and the values should be the SQLAlchemy types.
Examples
>>> pfs.as_positionfixes.to_postgis(conn_string, table_name) >>> ti.io.postgis.write_positionfixes_postgis(pfs, conn_string, table_name)
StaypointsAccessor
- class trackintel.model.staypoints.StaypointsAccessor(pandas_obj)[source]
A pandas accessor to treat (Geo)DataFrames as collections of Staypoints.
This will define certain methods and accessors, as well as make sure that the DataFrame adheres to some requirements.
Requires at least the following columns: [‘user_id’, ‘started_at’, ‘finished_at’]
Requires valid point geometries; the ‘index’ of the GeoDataFrame will be treated as unique identifier of the Staypoints.
For several usecases, the following additional columns are required: [‘elevation’, ‘purpose’, ‘is_activity’, ‘next_trip_id’, ‘prev_trip_id’, ‘trip_id’, location_id]
Notes
Staypoints are defined as location were a person did not move for a while. Under consideration of location uncertainty this means that a person stays within a close proximity for a certain amount of time. The exact definition is use-case dependent.
‘started_at’ and ‘finished_at’ are timezone aware pandas datetime objects.
Examples
>>> df.as_staypoints.generate_locations()
- property center
Return the center coordinate of this collection of staypoints.
- create_activity_flag(method='time_threshold', time_threshold=15.0, activity_column_name='is_activity')[source]
Add a flag whether or not a staypoint is considered an activity.
- Parameters
staypoints (GeoDataFrame (as trackintel staypoints)) – The original input staypoints
method ({'time_threshold'}, default = 'time_threshold') –
‘time_threshold’ : All staypoints with a duration greater than the time_threshold are considered an activity.
time_threshold (float, default = 15 (minutes)) – The time threshold for which a staypoint is considered an activity in minutes. Used by method ‘time_threshold’
activity_column_name (str , default = 'is_activity') – The name of the newly created column that holds the activity flag.
- Returns
staypoints – Original staypoints with the additional activity column
- Return type
GeoDataFrame (as trackintel staypoints)
Examples
>>> sp = sp.as_staypoints.create_activity_flag(method='time_threshold', time_threshold=15) >>> print(sp['activity'])
- generate_locations(method='dbscan', epsilon=100, num_samples=1, distance_metric='haversine', agg_level='user', print_progress=False, n_jobs=1)[source]
Generate locations from the staypoints.
- Parameters
staypoints (GeoDataFrame (as trackintel staypoints)) – The staypoints have to follow the standard definition for staypoints DataFrames.
method ({'dbscan'}) –
Method to create locations.
’dbscan’ : Uses the DBSCAN algorithm to cluster staypoints.
epsilon (float, default 100) – The epsilon for the ‘dbscan’ method. if ‘distance_metric’ is ‘haversine’ or ‘euclidean’, the unit is in meters.
num_samples (int, default 1) – The minimal number of samples in a cluster.
distance_metric ({'haversine', 'euclidean'}) – The distance metric used by the applied method. Any mentioned below are possible: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.pairwise_distances.html
agg_level ({'user','dataset'}) – The level of aggregation when generating locations: - ‘user’ : locations are generated independently per-user. - ‘dataset’ : shared locations are generated for all users.
print_progress (bool, default False) – If print_progress is True, the progress bar is displayed
n_jobs (int, default 1) – The maximum number of concurrently running jobs. If -1 all CPUs are used. If 1 is given, no parallel computing code is used at all, which is useful for debugging. See https://joblib.readthedocs.io/en/latest/parallel.html#parallel-reference-documentation for a detailed description
- Returns
sp (GeoDataFrame (as trackintel staypoints)) – The original staypoints with a new column
[`location_id`].locs (GeoDataFrame (as trackintel locations)) – The generated locations.
Examples
>>> sp.as_staypoints.generate_locations(method='dbscan', epsilon=100, num_samples=1)
- merge_staypoints(triplegs, max_time_gap='10min', agg={})[source]
Aggregate staypoints horizontally via time threshold.
- Parameters
staypoints (GeoDataFrame (as trackintel staypoints)) – The staypoints must contain a column location_id (see generate_locations function) and have to follow the standard trackintel definition for staypoints DataFrames.
triplegs (GeoDataFrame (as trackintel triplegs)) – The triplegs have to follow the standard definition for triplegs DataFrames.
max_time_gap (str or pd.Timedelta, default "10min") – Maximum duration between staypoints to still be merged. If str must be parsable by pd.to_timedelta.
agg (dict, optional) – Dictionary to aggregate the rows after merging staypoints. This dictionary is used as input to the pandas aggregate function: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.agg.html If empty, only the required columns of staypoints (which are [‘user_id’, ‘started_at’, ‘finished_at’]) are aggregated and returned. In order to return for example also the geometry column of the merged staypoints, set ‘agg={“geom”:”first”}’ to return the first geometry of the merged staypoints, or ‘agg={“geom”:”last”}’ to use the last one.
- Returns
sp – The new staypoints with the default columns and columns in agg, where staypoints at same location and close in time are aggregated.
- Return type
DataFrame
Notes
Due to the modification of the staypoint index, the relation between the staypoints and the corresponding positionfixes is broken after execution of this function! In explanation, the staypoint_id column of pfs does not necessarily correspond to an id in the new sp table that is returned from this function. The same holds for trips (if generated yet) where the staypoints contained in a trip might be merged in this function.
If there is a tripleg between two staypoints, the staypoints are not merged. If you for some reason want to merge such staypoints, simply pass an empty DataFrame for the tpls argument.
Examples
>>> # direct function call >>> ti.preprocessing.staypoints.merge_staypoints(staypoints=sp, triplegs=tpls) >>> # or using the trackintel datamodel >>> sp.as_staypoints.merge_staypoints(triplegs, max_time_gap="1h", agg={"geom":"first"})
- plot(out_filename=None, radius=100, positionfixes=None, plot_osm=False, axis=None)[source]
Plot staypoints (optionally to a file).
You can specify the radius with which each staypoint should be drawn, as well as if underlying positionfixes and OSM streets should be drawn. The data gets transformed to wgs84 for the plotting.
- Parameters
staypoints (GeoDataFrame (as trackintel staypoints)) – The staypoints to plot.
out_filename (str, optional) – The file to plot to, if this is not set, the plot will simply be shown.
radius (float, default 100 (meter)) – The radius in meter with which circles around staypoints should be drawn.
positionfixes (GeoDataFrame (as trackintel positionfixes), optional) – If available, some positionfixes that can additionally be plotted.
plot_osm (bool, default False) – If this is set to True, it will download an OSM street network and plot below the staypoints.
axis (matplotlib.pyplot.Artist, optional) – axis on which to draw the plot
Examples
>>> sp.as_staypoints.plot('output.png', radius=100, positionfixes=pfs, plot_osm=True)
- spatial_filter(areas, method='within', re_project=False)[source]
Filter staypoints, locations or triplegs with a geo extent.
- Parameters
source (GeoDataFrame (as trackintel datamodels)) – The source feature to perform the spatial filtering
areas (GeoDataFrame) – The areas used to perform the spatial filtering. Note, you can have multiple Polygons and it will return all the features intersect with ANY of those geometries.
method ({'within', 'intersects', 'crosses'}) –
The method to filter the ‘source’ GeoDataFrame
’within’ : return instances in ‘source’ where no points of these instances lies in the exterior of the ‘areas’ and at least one point of the interior of these instances lies in the interior of ‘areas’.
’intersects’: return instances in ‘source’ where the boundary or interior of these instances intersect in any way with those of the ‘areas’
’crosses’ : return instances in ‘source’ where the interior of these instances intersects the interior of the ‘areas’ but does not contain it, and the dimension of the intersection is less than the dimension of the one of the ‘areas’.
re_project (bool, default False) – If this is set to True, the ‘source’ will be projected to the coordinate reference system of ‘areas’
- Returns
ret_gdf – A new GeoDataFrame containing the features after the spatial filtering.
- Return type
GeoDataFrame (as trackintel datamodels)
Examples
>>> sp.as_staypoints.spatial_filter(areas, method="within", re_project=False)
- temporal_tracking_quality(granularity='all')[source]
Calculate per-user temporal tracking quality (temporal coverage).
- Parameters
df (GeoDataFrame (as trackintel datamodels)) – The source dataframe to calculate temporal tracking quality.
granularity ({"all", "day", "week", "weekday", "hour"}) – The level of which the tracking quality is calculated. The default “all” returns the overall tracking quality; “day” the tracking quality by days; “week” the quality by weeks; “weekday” the quality by day of the week (e.g, Mondays, Tuesdays, etc.) and “hour” the quality by hours.
- Returns
quality – A per-user per-granularity temporal tracking quality dataframe.
- Return type
DataFrame
Notes
Requires at least the following columns:
['user_id', 'started_at', 'finished_at']which means the function supports trackintelstaypoints,triplegs,tripsandtoursdatamodels and their combinations (e.g., staypoints and triplegs sequence).The temporal tracking quality is the ratio of tracking time and the total time extent. It is calculated and returned per-user in the defined
granularity. The time extents and the columns for the returnedqualitydf for differentgranularityare:all:time extent: between the latest “finished_at” and the earliest “started_at” for each user.
columns:
['user_id', 'quality'].
week:time extent: the whole week (604800 sec) for each user.
columns:
['user_id', 'week_monday', 'quality'].
day:time extent: the whole day (86400 sec) for each user
columns:
['user_id', 'day', 'quality']
weekdaytime extent: the whole day (86400 sec) * number of tracked weeks for each user for each user
columns:
['user_id', 'weekday', 'quality']
hour:time extent: the whole hour (3600 sec) * number of tracked days for each user
columns:
['user_id', 'hour', 'quality']
Examples
>>> # calculate overall tracking quality of staypoints >>> temporal_tracking_quality(sp, granularity="all") >>> # calculate per-day tracking quality of sp and tpls sequence >>> temporal_tracking_quality(sp_tpls, granularity="day")
- to_csv(filename, *args, **kwargs)[source]
Write staypoints to csv file.
Wraps the pandas to_csv function, but transforms the geometry into WKT before writing.
- Parameters
staypoints (GeoDataFrame (as trackintel staypoints)) – The staypoints to store to the CSV file.
filename (str) – The file to write to.
args – Additional arguments passed to pd.DataFrame.to_csv().
kwargs – Additional keyword arguments passed to pd.DataFrame.to_csv().
Examples
>>> tpls.as_triplegs.to_csv("export_tpls.csv")
- to_postgis(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)[source]
Stores staypoints to PostGIS. Usually, this is directly called on a staypoints DataFrame (see example below).
- Parameters
staypoints (GeoDataFrame (as trackintel staypoints)) – The staypoints to store to the database.
name (str) – The name of the table to write to.
con (str, sqlalchemy.engine.Connection or sqlalchemy.engine.Engine) – Connection string or active connection to PostGIS database.
schema (str, optional) – The schema (if the database supports this) where the table resides.
if_exists (str, {'fail', 'replace', 'append'}, default 'fail') –
How to behave if the table already exists.
fail: Raise a ValueError.
replace: Drop the table before inserting new values.
append: Insert new values to the existing table.
index (bool, default True) – Write DataFrame index as a column. Uses index_label as the column name in the table.
index_label (str or sequence, default None) – Column label for index column(s). If None is given (default) and index is True, then the index names are used.
chunksize (int, optional) – How many entries should be written at the same time.
dtype (dict of column name to SQL type, default None) – Specifying the datatype for columns. The keys should be the column names and the values should be the SQLAlchemy types.
Examples
>>> sp.as_staypoints.to_postgis(conn_string, table_name) >>> ti.io.postgis.write_staypoints_postgis(sp, conn_string, table_name)
TriplegsAccessor
- class trackintel.model.triplegs.TriplegsAccessor(pandas_obj)[source]
A pandas accessor to treat (Geo)DataFrames as collections of Tripleg.
This will define certain methods and accessors, as well as make sure that the DataFrame adheres to some requirements.
Requires at least the following columns: [‘user_id’, ‘started_at’, ‘finished_at’]
Requires valid line geometries; the ‘index’ of the GeoDataFrame will be treated as unique identifier of the triplegs
For several usecases, the following additional columns are required: [‘mode’, ‘trip_id’]
Notes
A Tripleg (also called stage) is defined as continuous movement without changing the mode of transport.
‘started_at’ and ‘finished_at’ are timezone aware pandas datetime objects.
Examples
>>> df.as_triplegs.plot()
- calculate_distance_matrix(Y=None, dist_metric='haversine', n_jobs=0, **kwds)[source]
Calculate a distance matrix based on a specific distance metric.
If only X is given, the pair-wise distances between all elements in X are calculated. If X and Y are given, the distances between all combinations of X and Y are calculated. Distances between elements of X and X, and distances between elements of Y and Y are not calculated.
- Parameters
X (GeoDataFrame (as trackintel staypoints or triplegs)) –
Y (GeoDataFrame (as trackintel staypoints or triplegs), optional) –
dist_metric ({'haversine', 'euclidean', 'dtw', 'frechet'}) –
The distance metric to be used for calculating the matrix.
For staypoints, common choice is ‘haversine’ or ‘euclidean’. This function wraps around the
pairwise_distancefunction from scikit-learn if only X is given and wraps around thescipy.spatial.distance.cdistfunction if X and Y are given. Therefore the following metrics are also accepted:via
scikit-learn: [‘cityblock’, ‘cosine’, ‘euclidean’, ‘l1’, ‘l2’, ‘manhattan’]via
scipy.spatial.distance: [‘braycurtis’, ‘canberra’, ‘chebyshev’, ‘correlation’, ‘dice’, ‘hamming’, ‘jaccard’, ‘kulsinski’, ‘mahalanobis’, ‘minkowski’, ‘rogerstanimoto’, ‘russellrao’, ‘seuclidean’, ‘sokalmichener’, ‘sokalsneath’, ‘sqeuclidean’, ‘yule’]For triplegs, common choice is ‘dtw’ or ‘frechet’. This function uses the implementation from similaritymeasures.
n_jobs (int) – Number of cores to use: ‘dtw’, ‘frechet’ and all distance metrics from pairwise_distance (only available if only X is given) are parallelized.
**kwds – optional keywords passed to the distance functions.
- Returns
D – matrix of shape (len(X), len(X)) or of shape (len(X), len(Y)) if Y is provided.
- Return type
np.array
Examples
>>> calculate_distance_matrix(staypoints, dist_metric="haversine") >>> calculate_distance_matrix(triplegs_1, triplegs_2, dist_metric="dtw")
- calculate_modal_split(freq=None, metric='count', per_user=False, norm=False)[source]
Calculate the modal split of triplegs
- Parameters
tpls (GeoDataFrame (as trackintel triplegs)) – triplegs require the column mode.
freq (str) – frequency string passed on as freq keyword to the pandas.Grouper class. If freq=None the modal split is calculated on all data. A list of possible values can be found here.
metric ({'count', 'distance', 'duration'}) – Aggregation used to represent the modal split. ‘distance’ returns in the same unit as the crs. ‘duration’ returns values in seconds.
per_user (bool, default: False) – If True the modal split is calculated per user
norm (bool, default: False) – If True every row of the modal split is normalized to 1
- Returns
modal_split – The modal split represented as pandas Dataframe with (optionally) a multi-index. The index can have the levels: (‘user_id’, ‘timestamp’) and every mode as a column.
- Return type
DataFrame
Notes
freq=’W-MON’ is used for a weekly aggregation that starts on mondays.
If freq=None and per_user=False are passed the modal split collapses to a single column.
The modal split can be visualized using
trackintel.visualization.modal_split.plot_modal_split()Examples
>>> triplegs.calculate_modal_split() >>> tripleg.calculate_modal_split(freq='W-MON', metric='distance')
- generate_trips(triplegs, gap_threshold=15, add_geometry=True)[source]
Generate trips based on staypoints and triplegs.
- Parameters
staypoints (GeoDataFrame (as trackintel staypoints)) –
triplegs (GeoDataFrame (as trackintel triplegs)) –
gap_threshold (float, default 15 (minutes)) – Maximum allowed temporal gap size in minutes. If tracking data is missing for more than gap_threshold minutes, then a new trip begins after the gap.
add_geometry (bool default True) – If True, the start and end coordinates of each trip are added to the output table in a geometry column “geom” of type MultiPoint. Set add_geometry=False for better runtime performance (if coordinates are not required).
print_progress (bool, default False) – If print_progress is True, the progress bar is displayed
- Returns
sp (GeoDataFrame (as trackintel staypoints)) – The original staypoints with new columns
[`trip_id`, `prev_trip_id`, `next_trip_id`].tpls (GeoDataFrame (as trackintel triplegs)) – The original triplegs with a new column
[`trip_id`].trips ((Geo)DataFrame (as trackintel trips)) – The generated trips.
Notes
Trips are an aggregation level in transport planning that summarize all movement and all non-essential actions (e.g., waiting) between two relevant activities. The function returns altered versions of the input staypoints and triplegs. Staypoints receive the fields [trip_id prev_trip_id and next_trip_id], triplegs receive the field [trip_id]. The following assumptions are implemented
If we do not record a person for more than gap_threshold minutes, we assume that the person performed an activity in the recording gap and split the trip at the gap.
Trips that start/end in a recording gap can have an unknown origin/destination
There are no trips without a (recorded) tripleg
Trips optionally have their start and end point as geometry of type MultiPoint, if add_geometry==True
If the origin (or destination) staypoint is unknown, and add_geometry==True, the origin (and destination) geometry is set as the first coordinate of the first tripleg (or the last coordinate of the last tripleg), respectively. Trips with missing values can still be identified via col origin_staypoint_id.
Examples
>>> from trackintel.preprocessing.triplegs import generate_trips >>> staypoints, triplegs, trips = generate_trips(staypoints, triplegs)
trips can also be directly generated using the tripleg accessor >>> staypoints, triplegs, trips = triplegs.as_triplegs.generate_trips(staypoints)
- get_speed(positionfixes=None, method='tpls_speed')[source]
Compute the average speed per positionfix for each tripleg (in m/s)
- Parameters
triplegs (GeoDataFrame (as trackintel triplegs)) – The generated triplegs as returned by ti.preprocessing.positionfixes.generate_triplegs
(Optional) (positionfixes) – The positionfixes as returned by ti.preprocessing.positionfixes.generate_triplegs. Only required if the method is ‘pfs_mean_speed’. In addition the standard columns it must include the column
[`tripleg_id`].method (str) – Method how the speed is computed, one of {tpls_speed, pfs_mean_speed}. The ‘tpls_speed’ method simply divides the overall tripleg distance by its duration, while the ‘pfs_mean_speed’ method is the mean pfs speed.
- Returns
tpls – The original triplegs with a new column
[`speed`]. The speed is given in m/s.- Return type
GeoDataFrame (as trackintel triplegs)
- plot(out_filename=None, positionfixes=None, staypoints=None, staypoints_radius=100, plot_osm=False, axis=None)[source]
Plot triplegs (optionally to a file).
You can specify several other datasets to be plotted beneath the triplegs, as well as if the OSM streets should be drawn. The data gets transformed to wgs84 for the plotting.
- Parameters
triplegs (GeoDataFrame (as trackintel triplegs)) – The triplegs to plot.
out_filename (str, optional) – The file to plot to, if this is not set, the plot will simply be shown.
positionfixes (GeoDataFrame (as trackintel positionfixes), optional) – If available, some positionfixes that can additionally be plotted.
staypoints (GeoDataFrame (as trackintel staypoints), optional) – If available, some staypoints that can additionally be plotted.
staypoints_radius (float, default 100 (meter)) – The radius in meter with which circles around staypoints should be drawn.
plot_osm (bool, default False) – If this is set to True, it will download an OSM street network and plot below the triplegs.
axis (matplotlib.pyplot.Artist, optional) – axis on which to draw the plot
Example
>>> tpls.as_triplegs.plot('output.png', positionfixes=pfs, staypoints=sp, plot_osm=True)
- predict_transport_mode(method='simple-coarse', **kwargs)[source]
Predict the transport mode of triplegs.
Predict/impute the transport mode that was likely chosen to cover the given tripleg, e.g., car, bicycle, or walk.
- Parameters
triplegs (GeoDataFrame (as trackintel triplegs)) – The original input triplegs.
method ({'simple-coarse'}) –
The following methods are available for transport mode inference/prediction:
’simple-coarse’ : Uses simple heuristics to predict coarse transport classes.
- Returns
triplegs – The triplegs with added column mode, containing the predicted transport modes.
- Return type
GeoDataFrame (as trackintel triplegs)
Notes
simple-coarsemethod includes{'slow_mobility', 'motorized_mobility', 'fast_mobility'}. In the default classification,slow_mobility(<15 km/h) includes transport modes such as walking or cycling,motorized_mobility(<100 km/h) modes such as car or train, andfast_mobility(>100 km/h) modes such as high-speed rail or airplanes. These categories are default values and can be overwritten using the keyword argument categories.Examples
>>> tpls = tpls.as_triplegs.predict_transport_mode() >>> print(tpls["mode"])
- spatial_filter(areas, method='within', re_project=False)[source]
Filter staypoints, locations or triplegs with a geo extent.
- Parameters
source (GeoDataFrame (as trackintel datamodels)) – The source feature to perform the spatial filtering
areas (GeoDataFrame) – The areas used to perform the spatial filtering. Note, you can have multiple Polygons and it will return all the features intersect with ANY of those geometries.
method ({'within', 'intersects', 'crosses'}) –
The method to filter the ‘source’ GeoDataFrame
’within’ : return instances in ‘source’ where no points of these instances lies in the exterior of the ‘areas’ and at least one point of the interior of these instances lies in the interior of ‘areas’.
’intersects’: return instances in ‘source’ where the boundary or interior of these instances intersect in any way with those of the ‘areas’
’crosses’ : return instances in ‘source’ where the interior of these instances intersects the interior of the ‘areas’ but does not contain it, and the dimension of the intersection is less than the dimension of the one of the ‘areas’.
re_project (bool, default False) – If this is set to True, the ‘source’ will be projected to the coordinate reference system of ‘areas’
- Returns
ret_gdf – A new GeoDataFrame containing the features after the spatial filtering.
- Return type
GeoDataFrame (as trackintel datamodels)
Examples
>>> sp.as_staypoints.spatial_filter(areas, method="within", re_project=False)
- temporal_tracking_quality(granularity='all')[source]
Calculate per-user temporal tracking quality (temporal coverage).
- Parameters
df (GeoDataFrame (as trackintel datamodels)) – The source dataframe to calculate temporal tracking quality.
granularity ({"all", "day", "week", "weekday", "hour"}) – The level of which the tracking quality is calculated. The default “all” returns the overall tracking quality; “day” the tracking quality by days; “week” the quality by weeks; “weekday” the quality by day of the week (e.g, Mondays, Tuesdays, etc.) and “hour” the quality by hours.
- Returns
quality – A per-user per-granularity temporal tracking quality dataframe.
- Return type
DataFrame
Notes
Requires at least the following columns:
['user_id', 'started_at', 'finished_at']which means the function supports trackintelstaypoints,triplegs,tripsandtoursdatamodels and their combinations (e.g., staypoints and triplegs sequence).The temporal tracking quality is the ratio of tracking time and the total time extent. It is calculated and returned per-user in the defined
granularity. The time extents and the columns for the returnedqualitydf for differentgranularityare:all:time extent: between the latest “finished_at” and the earliest “started_at” for each user.
columns:
['user_id', 'quality'].
week:time extent: the whole week (604800 sec) for each user.
columns:
['user_id', 'week_monday', 'quality'].
day:time extent: the whole day (86400 sec) for each user
columns:
['user_id', 'day', 'quality']
weekdaytime extent: the whole day (86400 sec) * number of tracked weeks for each user for each user
columns:
['user_id', 'weekday', 'quality']
hour:time extent: the whole hour (3600 sec) * number of tracked days for each user
columns:
['user_id', 'hour', 'quality']
Examples
>>> # calculate overall tracking quality of staypoints >>> temporal_tracking_quality(sp, granularity="all") >>> # calculate per-day tracking quality of sp and tpls sequence >>> temporal_tracking_quality(sp_tpls, granularity="day")
- to_csv(filename, *args, **kwargs)[source]
Write triplegs to csv file.
Wraps the pandas to_csv function, but transforms the geometry into WKT before writing.
- Parameters
triplegs (GeoDataFrame (as trackintel triplegs)) – The triplegs to store to the CSV file.
filename (str) – The file to write to.
args – Additional arguments passed to pd.DataFrame.to_csv().
kwargs – Additional keyword arguments passed to pd.DataFrame.to_csv().
Examples
>>> tpls.as_triplegs.to_csv("export_tpls.csv")
- to_postgis(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)[source]
Stores triplegs to PostGIS. Usually, this is directly called on a triplegs DataFrame (see example below).
- Parameters
triplegs (GeoDataFrame (as trackintel triplegs)) – The triplegs to store to the database.
name (str) – The name of the table to write to.
con (str, sqlalchemy.engine.Connection or sqlalchemy.engine.Engine) – Connection string or active connection to PostGIS database.
schema (str, optional) – The schema (if the database supports this) where the table resides.
if_exists (str, {'fail', 'replace', 'append'}, default 'fail') –
How to behave if the table already exists.
fail: Raise a ValueError.
replace: Drop the table before inserting new values.
append: Insert new values to the existing table.
index (bool, default True) – Write DataFrame index as a column. Uses index_label as the column name in the table.
index_label (str or sequence, default None) – Column label for index column(s). If None is given (default) and index is True, then the index names are used.
chunksize (int, optional) – How many entries should be written at the same time.
dtype (dict of column name to SQL type, default None) – Specifying the datatype for columns. The keys should be the column names and the values should be the SQLAlchemy types.
Examples
>>> tpls.as_triplegs.to_postgis(conn_string, table_name) >>> ti.io.postgis.write_triplegs_postgis(tpls, conn_string, table_name)
LocationsAccessor
- class trackintel.model.locations.LocationsAccessor(pandas_obj)[source]
A pandas accessor to treat (Geo)DataFrames as collections of locations.
This will define certain methods and accessors, as well as make sure that the DataFrame adheres to some requirements.
Requires at least the following columns: [‘user_id’, ‘center’]
For several usecases, the following additional columns are required: [‘elevation’, ‘extent’]
Notes
Locations are spatially aggregated Staypoints where a user frequently visits.
Examples
>>> df.as_locations.plot()
- plot(out_filename=None, radius=150, positionfixes=None, staypoints=None, staypoints_radius=100, plot_osm=False, axis=None)[source]
Plot locations (optionally to a file).
Optionally, you can specify several other datasets to be plotted beneath the locations.
- Parameters
locations (GeoDataFrame (as trackintel locations)) – The locations to plot.
out_filename (str, optional) – The file to plot to, if this is not set, the plot will simply be shown.
radius (float, default 150 (meter)) – The radius in meter with which circles around locations should be drawn.
positionfixes (GeoDataFrame (as trackintel positionfixes), optional) – If available, some positionfixes that can additionally be plotted.
staypoints (GeoDataFrame (as trackintel staypoints), optional) – If available, some staypoints that can additionally be plotted.
staypoints_radius (float, default 100 (meter)) – The radius in meter with which circles around staypoints should be drawn.
plot_osm (bool, default False) – If this is set to True, it will download an OSM street network and plot below the staypoints.
axis (matplotlib.pyplot.Artist, optional) – axis on which to draw the plot
Examples
>>> locs.as_locations.plot('output.png', radius=200, positionfixes=pfs, staypoints=sp, plot_osm=True)
- spatial_filter(areas, method='within', re_project=False)[source]
Filter staypoints, locations or triplegs with a geo extent.
- Parameters
source (GeoDataFrame (as trackintel datamodels)) – The source feature to perform the spatial filtering
areas (GeoDataFrame) – The areas used to perform the spatial filtering. Note, you can have multiple Polygons and it will return all the features intersect with ANY of those geometries.
method ({'within', 'intersects', 'crosses'}) –
The method to filter the ‘source’ GeoDataFrame
’within’ : return instances in ‘source’ where no points of these instances lies in the exterior of the ‘areas’ and at least one point of the interior of these instances lies in the interior of ‘areas’.
’intersects’: return instances in ‘source’ where the boundary or interior of these instances intersect in any way with those of the ‘areas’
’crosses’ : return instances in ‘source’ where the interior of these instances intersects the interior of the ‘areas’ but does not contain it, and the dimension of the intersection is less than the dimension of the one of the ‘areas’.
re_project (bool, default False) – If this is set to True, the ‘source’ will be projected to the coordinate reference system of ‘areas’
- Returns
ret_gdf – A new GeoDataFrame containing the features after the spatial filtering.
- Return type
GeoDataFrame (as trackintel datamodels)
Examples
>>> sp.as_staypoints.spatial_filter(areas, method="within", re_project=False)
- to_csv(filename, *args, **kwargs)[source]
Write locations to csv file.
Wraps the pandas to_csv function, but transforms the center (and extent) into WKT before writing.
- Parameters
locations (GeoDataFrame (as trackintel locations)) – The locations to store to the CSV file.
filename (str) – The file to write to.
args – Additional arguments passed to pd.DataFrame.to_csv().
kwargs – Additional keyword arguments passed to pd.DataFrame.to_csv().
Examples
>>> locs.as_locations.to_csv("export_locs.csv")
- to_postgis(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)[source]
Stores locations to PostGIS. Usually, this is directly called on a locations DataFrame (see example below).
- Parameters
locations (GeoDataFrame (as trackintel locations)) – The locations to store to the database.
name (str) – The name of the table to write to.
con (str, sqlalchemy.engine.Connection or sqlalchemy.engine.Engine) – Connection string or active connection to PostGIS database.
schema (str, optional) – The schema (if the database supports this) where the table resides.
if_exists (str, {'fail', 'replace', 'append'}, default 'fail') –
How to behave if the table already exists.
fail: Raise a ValueError.
replace: Drop the table before inserting new values.
append: Insert new values to the existing table.
index (bool, default True) – Write DataFrame index as a column. Uses index_label as the column name in the table.
index_label (str or sequence, default None) – Column label for index column(s). If None is given (default) and index is True, then the index names are used.
chunksize (int, optional) – How many entries should be written at the same time.
dtype (dict of column name to SQL type, default None) – Specifying the datatype for columns. The keys should be the column names and the values should be the SQLAlchemy types.
Examples
>>> locs.as_locations.to_postgis(conn_string, table_name) >>> ti.io.postgis.write_locations_postgis(locs, conn_string, table_name)
TripsAccessor
- class trackintel.model.trips.TripsAccessor(pandas_obj)[source]
A pandas accessor to treat (Geo)DataFrames as collections of trips.
This will define certain methods and accessors, as well as make sure that the DataFrame adheres to some requirements.
Requires at least the following columns: [‘user_id’, ‘started_at’, ‘finished_at’, ‘origin_staypoint_id’, ‘destination_staypoint_id’]
The ‘index’ of the (Geo)DataFrame will be treated as unique identifier of the Trips
Trips have an optional geometry of type MultiPoint which describes the start and the end point of the trip
For several usecases, the following additional columns are required: [‘origin_purpose’, ‘destination_purpose’, ‘modes’, ‘primary_mode’, ‘tour_id’]
Notes
Trips are an aggregation level in transport planning that summarize all movement and all non-essential actions (e.g., waiting) between two relevant activities. The following assumptions are implemented
If we do not record a person for more than gap_threshold minutes, we assume that the person performed an activity in the recording gap and split the trip at the gap.
Trips that start/end in a recording gap can have an unknown origin/destination staypoint id.
If the origin (or destination) staypoint is unknown (and a geometry column exists), the origin/destination geometry is set as the first coordinate of the first tripleg (or the last coordinate of the last tripleg)
There are no trips without a (recorded) tripleg.
‘started_at’ and ‘finished_at’ are timezone aware pandas datetime objects.
Examples
>>> df.as_trips.plot()
- generate_tours(*args, **kwargs)[source]
Generate tours based on trips (and optionally staypoint locations).
- plot(*args, **kwargs)[source]
Plot this collection of trips.
See
trackintel.visualization.trips.plot_trips().
- temporal_tracking_quality(granularity='all')[source]
Calculate per-user temporal tracking quality (temporal coverage).
- Parameters
df (GeoDataFrame (as trackintel datamodels)) – The source dataframe to calculate temporal tracking quality.
granularity ({"all", "day", "week", "weekday", "hour"}) – The level of which the tracking quality is calculated. The default “all” returns the overall tracking quality; “day” the tracking quality by days; “week” the quality by weeks; “weekday” the quality by day of the week (e.g, Mondays, Tuesdays, etc.) and “hour” the quality by hours.
- Returns
quality – A per-user per-granularity temporal tracking quality dataframe.
- Return type
DataFrame
Notes
Requires at least the following columns:
['user_id', 'started_at', 'finished_at']which means the function supports trackintelstaypoints,triplegs,tripsandtoursdatamodels and their combinations (e.g., staypoints and triplegs sequence).The temporal tracking quality is the ratio of tracking time and the total time extent. It is calculated and returned per-user in the defined
granularity. The time extents and the columns for the returnedqualitydf for differentgranularityare:all:time extent: between the latest “finished_at” and the earliest “started_at” for each user.
columns:
['user_id', 'quality'].
week:time extent: the whole week (604800 sec) for each user.
columns:
['user_id', 'week_monday', 'quality'].
day:time extent: the whole day (86400 sec) for each user
columns:
['user_id', 'day', 'quality']
weekdaytime extent: the whole day (86400 sec) * number of tracked weeks for each user for each user
columns:
['user_id', 'weekday', 'quality']
hour:time extent: the whole hour (3600 sec) * number of tracked days for each user
columns:
['user_id', 'hour', 'quality']
Examples
>>> # calculate overall tracking quality of staypoints >>> temporal_tracking_quality(sp, granularity="all") >>> # calculate per-day tracking quality of sp and tpls sequence >>> temporal_tracking_quality(sp_tpls, granularity="day")
- to_csv(filename, *args, **kwargs)[source]
Write trips to csv file.
Wraps the pandas to_csv function. Geometry get transformed to WKT before writing.
- Parameters
trips ((Geo)DataFrame (as trackintel trips)) – The trips to store to the CSV file.
filename (str) – The file to write to.
args – Additional arguments passed to pd.DataFrame.to_csv().
kwargs – Additional keyword arguments passed to pd.DataFrame.to_csv().
Examples
>>> trips.as_trips.to_csv("export_trips.csv")
- to_postgis(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None)[source]
Stores trips to PostGIS. Usually, this is directly called on a trips DataFrame (see example below).
- Parameters
trips (GeoDataFrame (as trackintel trips)) – The trips to store to the database.
name (str) – The name of the table to write to.
con (str, sqlalchemy.engine.Connection or sqlalchemy.engine.Engine) – Connection string or active connection to PostGIS database.
schema (str, optional) – The schema (if the database supports this) where the table resides.
if_exists (str, {'fail', 'replace', 'append'}, default 'fail') –
How to behave if the table already exists.
fail: Raise a ValueError.
replace: Drop the table before inserting new values.
append: Insert new values to the existing table.
index (bool, default True) – Write DataFrame index as a column. Uses index_label as the column name in the table.
index_label (str or sequence, default None) – Column label for index column(s). If None is given (default) and index is True, then the index names are used.
chunksize (int, optional) – How many entries should be written at the same time.
dtype (dict of column name to SQL type, default None) – Specifying the datatype for columns. The keys should be the column names and the values should be the SQLAlchemy types.
Examples
>>> trips.as_trips.to_postgis(conn_string, table_name) >>> ti.io.postgis.write_trips_postgis(trips, conn_string, table_name)
ToursAccessor
- class trackintel.model.tours.ToursAccessor(pandas_obj)[source]
A pandas accessor to treat DataFrames as collections of Tours.
Requires at least the following columns: [‘user_id’, ‘started_at’, ‘finished_at’]
The ‘index’ of the DataFrame will be treated as unique identifier of the Tours
For several usecases, the following additional columns are required: [‘location_id’, ‘journey’, ‘origin_staypoint_id’, ‘destination_staypoint_id’]
Notes
Tours are an aggregation level in transport planning that summarize all trips until a person returns to the same location. Tours starting and ending at home (=journey) are especially important.
‘started_at’ and ‘finished_at’ are timezone aware pandas datetime objects.
Examples
>>> df.as_tours.plot()
- plot(*args, **kwargs)[source]
Plot this collection of tours.
See
trackintel.visualization.tours.plot_tours().
Data Model (SQL)
For a general description of the data model, please refer to the Model. You can download the complete SQL script here in case you want to quickly set up a database. Also take a look at the example on github.
The positionfixes table contains all positionfixes (i.e., all individual GPS trackpoints, consisting of longitude, latitude and timestamp) of all users. They are not only linked to a user, but also (potentially, if this link has already been made) to a tripleg or a staypoint:
CREATE TABLE positionfixes (
-- Common to all tables.
id bigint NOT NULL,
user_id bigint NOT NULL,
-- References to foreign tables.
tripleg_id bigint,
staypoint_id bigint,
-- Temporal attributes.
tracked_at timestamp with time zone NOT NULL,
-- Spatial attributes.
elevation double precision,
geom geometry(Point, 4326),
-- Constraints.
CONSTRAINT positionfixes_pkey PRIMARY KEY (id)
);
The staypoints table contains all stay points, i.e., points where a user stayed for a certain amount of time. They are linked to a user, as well as (potentially) to a trip and location. Depending on the purpose and time spent, a staypoint can be an activity, i.e., a meaningful destination of movement:
CREATE TABLE staypoints (
-- Common to all tables.
id bigint NOT NULL,
user_id bigint NOT NULL,
-- References to foreign tables.
trip_id bigint,
location_id bigint,
-- Temporal attributes.
started_at timestamp with time zone NOT NULL,
finished_at timestamp with time zone NOT NULL,
-- Attributes related to the activity performed at the staypoint.
purpose_detected character varying,
purpose_validated character varying,
validated boolean,
validated_at timestamp with time zone,
activity boolean,
-- Spatial attributes.
elevation double precision,
geom geometry(Point, 4326),
-- Constraints.
CONSTRAINT staypoints_pkey PRIMARY KEY (id)
);
The triplegs table contains all triplegs, i.e., journeys that have been taken with a single mode of transport. They are linked to both a user, as well as a trip and if applicable, a public transport case:
CREATE TABLE triplegs (
-- Common to all tables.
id bigint NOT NULL,
user_id bigint NOT NULL,
-- References to foreign tables.
trip_id bigint,
-- Temporal attributes.
started_at timestamp with time zone NOT NULL,
finished_at timestamp with time zone NOT NULL,
-- Attributes related to the transport mode used for this tripleg.
mode_detected character varying,
mode_validated character varying,
validated boolean,
validated_at timestamp with time zone,
-- Spatial attributes.
-- The raw geometry is unprocessed, directly made up from the positionfixes. The column
-- 'geom' contains processed (e.g., smoothened, map matched, etc.) data.
geom_raw geometry(Linestring, 4326),
geom geometry(Linestring, 4326),
-- Constraints.
CONSTRAINT triplegs_pkey PRIMARY KEY (id)
);
The locations table contains all locations, i.e., somehow created (e.g., from clustering staypoints) meaningful locations:
CREATE TABLE locations (
-- Common to all tables.
id bigint NOT NULL,
user_id bigint,
-- Spatial attributes.
elevation double precision,
extent geometry(Polygon, 4326),
center geometry(Point, 4326),
-- Constraints.
CONSTRAINT locations_pkey PRIMARY KEY (id)
);
The trips table contains all trips, i.e., collection of trip legs going from one
activity (staypoint with activity==True) to another. They are simply linked to a user:
CREATE TABLE trips (
-- Common to all tables.
id bigint NOT NULL,
user_id integer NOT NULL,
-- References to foreign tables.
origin_staypoint_id bigint,
destination_staypoint_id bigint,
-- Temporal attributes.
started_at timestamp with time zone NOT NULL,
finished_at timestamp with time zone NOT NULL,
-- Constraints.
CONSTRAINT trips_pkey PRIMARY KEY (id)
);
The tours table contains all tours, i.e., sequence of trips which start and end
at the same location (in case of journey==True this location is home).
They are linked to a user:
CREATE TABLE tours (
-- Common to all tables.
id bigint NOT NULL,
user_id integer NOT NULL,
-- References to foreign tables.
location_id bigint,
-- Temporal attributes.
started_at timestamp with time zone NOT NULL,
finished_at timestamp with time zone NOT NULL,
-- Specific attributes.
journey bool,
-- Constraints.
CONSTRAINT tours_pkey PRIMARY KEY (id)
);